Let’s try an experiment. If we start with some large body of text — post-war American novels, say, or twentieth-century British newspapers — and count all the occurrences of all the words in those texts, we can put together a fairly accurate list of the most popular words in English. The word “the” would be at the top, followed by “of” and then “and”. With this list of word counts in hand, you could turn to any other similar body of work — British novels or American newspapers, for example — and have a good idea of how often you’d expect to find each of the words on your list. Simple enough.
Next, imagine that you throw away those word counts. You keep only the list of words themselves, ordered from most to least common. You don’t know if “the” occurs twice as often as “of” or a hundred times more than it. It turns out that you can still predict how often you’re likely to encounter a given word: knowing only that “the” is the most common word, “of” is second most common, “and” is third, and so on, it is possible to guess with quite startling accuracy exactly how likely you are to encounter a given word. The mathematical relationship that underpins all this is called Zipf’s Law, named for its discovery in the 1930s by Kingsley Zipf, a professor of German at Harvard,1 and it is very simple indeed. Eric Weisstein’s excellent Mathworld site explains it as follows:
In the English language, the probability of encountering the rth most common word is given roughly by P(r) = 0.1/r for r up to 1000 or so.2
To put some numbers on it, you should encounter the word “the” around every ten words, equating to a probability of 0.1/1 = 0.1; “of” should occur every twenty words or so, from 0.1/2 = 0.05; “and” will appear once every thirty words or thereabouts, from 0.1/3; and so on. This is an instance of what is called an inverse power law, and if you plot these numbers on a logarithmic scale you get a shockingly straight line. Here’s an example of the raw numbers for the fifty most common words in the so-called Brown Corpus, a million-word collection of texts compiled between 1964 and 1979:3
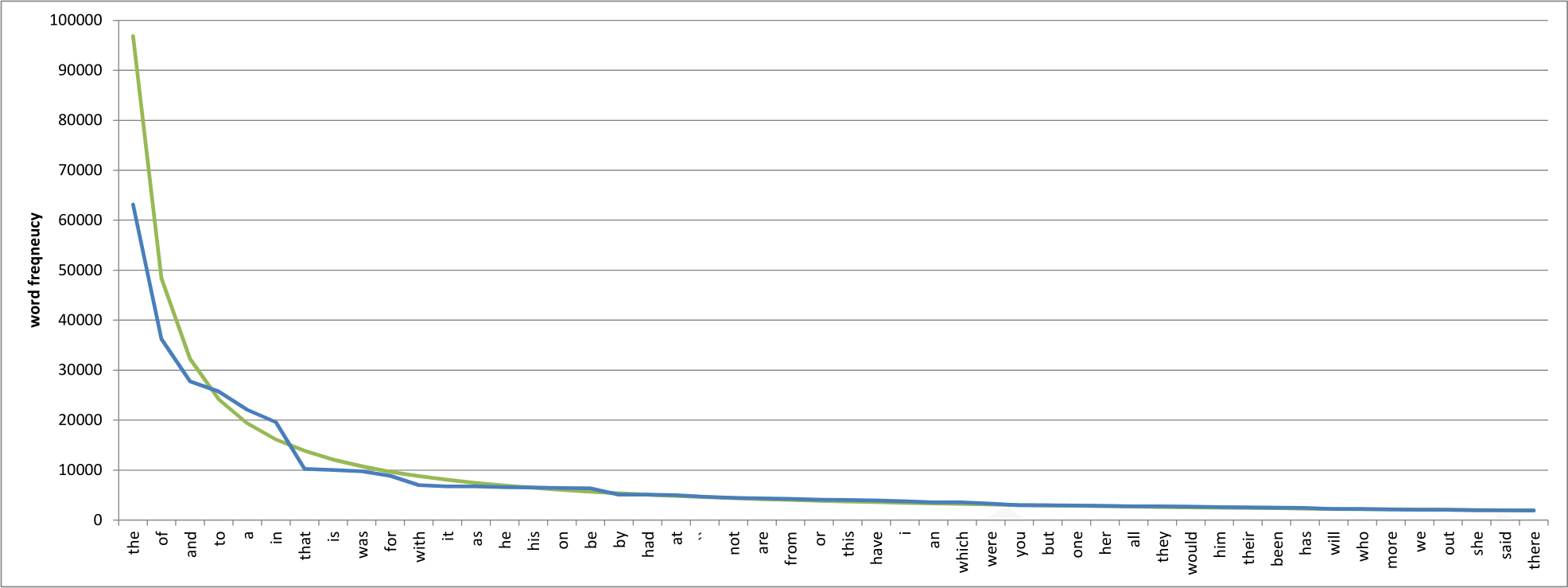
Not bad, I think. I’ve overlaid the expected word counts (in green) as predicted by Zipf’s Law, and it looks fairly convincing. If we make each axis logarithmic rather than linear, we get this:
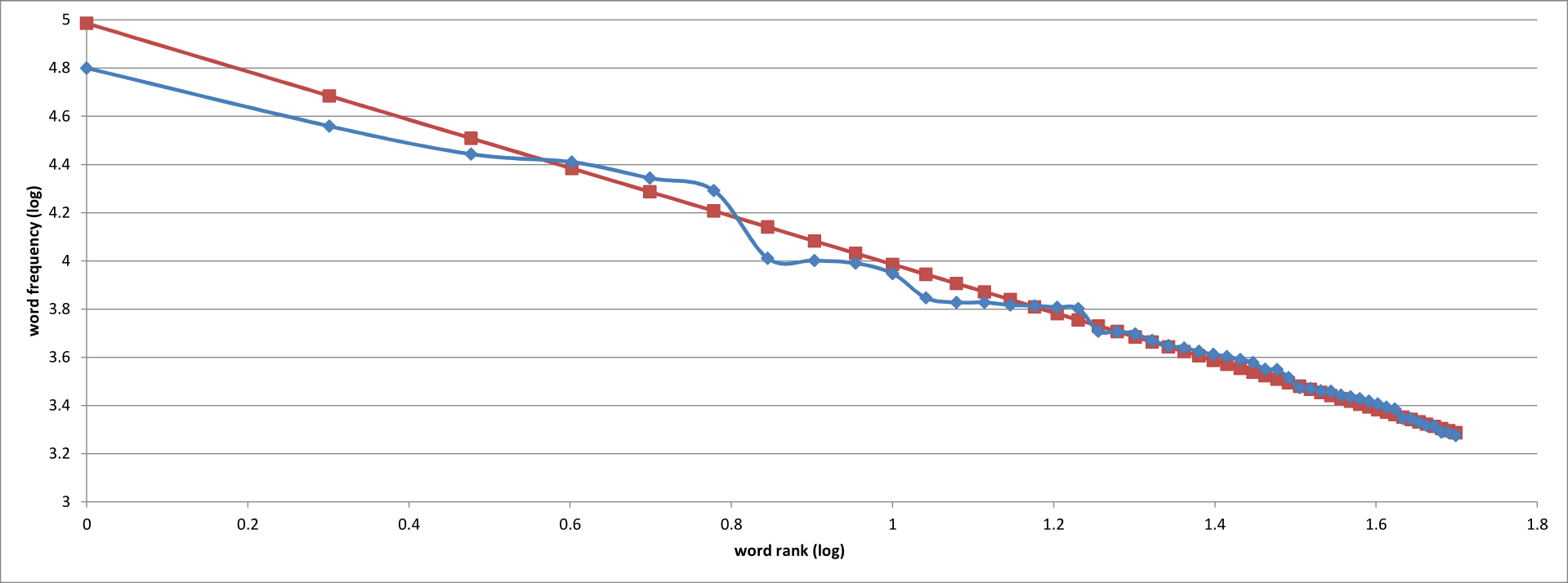
Better! The maths behind this are quite involved, but the effect of viewing the data on logarithmic axes is to show the perfectly straight line predicted by Zipf’s Law. Again, our data looks good — not a perfect fit, but our actual word counts conform to the predicted values relatively closely. So far, so good. It look as though Zipf’s Law is in full effect in our million-word test case.
Now the weird thing about Zipf’s Law is that is can be arrived at only by observation. There are no verbs, conjunctions and or definite articles out there in nature, waiting for their physical properties to be discovered; our ancestors made them up as they went along and yet somehow we have constructed a language that adheres uncannily to an abstract mathematical idea. Why should the word “the” occur twice as often as “of”, three times as often as “and”, and so on? No-one really knows.
What is even odder is that inverse power laws crop up again and again in what should, by rights, be entirely random groups of things; Zipf’s Law is to words what Benford’s Law is to digits, and Benford’s Law is absolutely everywhere. The distribution of digits in house numbers, prime numbers, the half-lives of radioactive isotopes, and even the lengths in kilometres of the world’s rivers all follow inverse power laws, with the digit 1 being most prevalent by far and the others falling off behind it. Benford’s Law is so reliable that economists use it to detect fraud: if they don’t see a logarithmic distribution of digits in a given set of accounts, with 1 enthroned at the top, they know that someone has been doctoring the figures.4
My thought, then, was this: does punctuation follow some variant of Zipf’s Law? If we count all the marks of punctuation in some suitably large dataset of English texts, do we see a logarithmic distribution in them? There are many fewer unique punctuation marks than there are words, of course, but then Benford’s Law works quite happily with only ten digits to play with. It’s intriguing to wonder: were the writers and editors who invented the comma, full stop and apostrophe moved by the same inexplicable law that governs baseball statistics, the Dow Jones index and the size of files on your PC? I wrote a computer program to find out.
I started by looking at the Brown Corpus, but given that it contains a paltry million words or so there aren’t all that many punctuation marks to be found. I turned instead to Project Gutenberg, which makes out-of-copyright books available in a variety of formats, and downloaded twelve of the most popular works.* Next, I counted the occurrences of all marks of punctuation and plotted them both as raw numbers and as log-log graphs of their occurrences and rank numbers of those same values. Here’s the equivalent of our first graph, only for marks of punctuation rather than words:
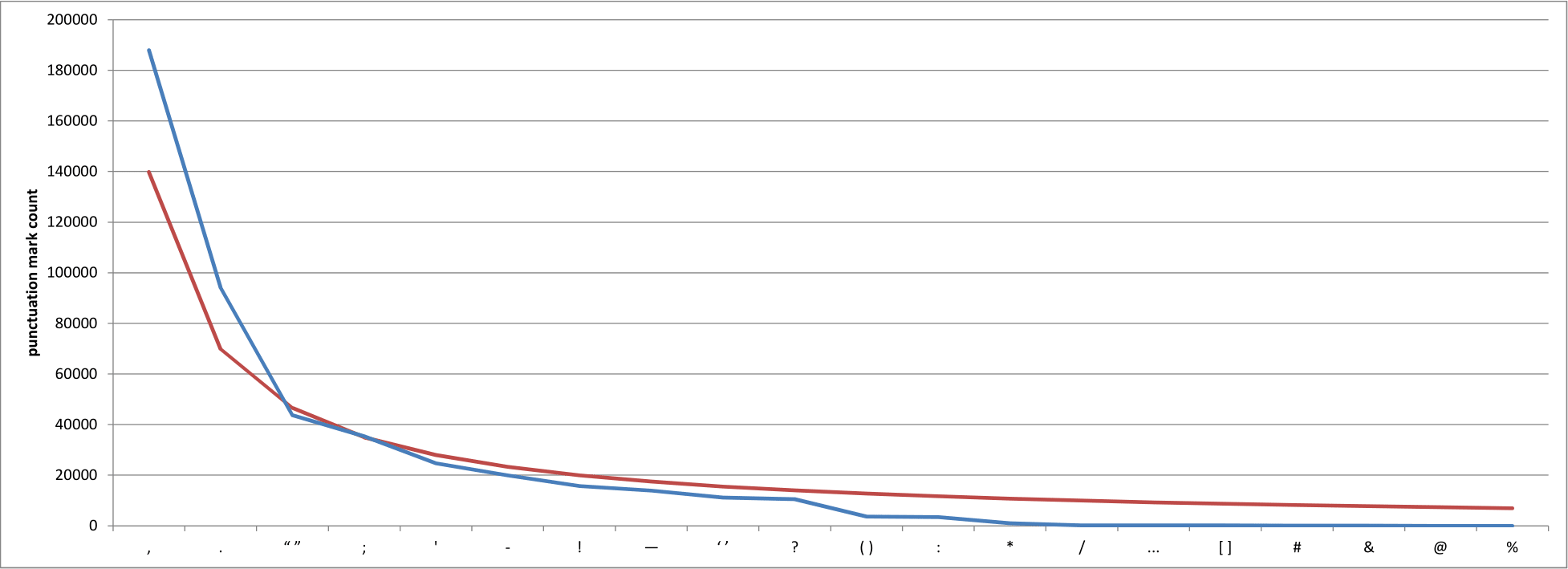
Well then. This looks familiar.
We’ll come to the red line in a moment, but let’s stick with the blue line for now. It represents the number of times that each of the marks of punctuation along the x-axis occurred in my ad hoc Project Gutenberg corpus, with the comma in pole position and the full stop around 50% behind it. There’s a bit of a jump down to the paired quotation mark,† but the fact that the quotation mark is up there at all is doubtless to be expected from the dialog-heavy novels that make up the bulk of the works I analysed. The semicolon is is fourth position, likely because my texts are predominantly of the nineteenth century, and the apostrophe follows it in fifth.
Now to the red line. If you remember, Zipf’s Law says that the probability P of encountering a word with ranking r is given by P(r) = 0.1/r. Guessing that there’s a similar distribution for punctuation marks, I played around with a variety of different values for the numerator of the fraction, eventually settling on 0.3 as a reasonable proposition. The red line, then, is my predicted distribution of punctuation marks, as given by the equation P(r) = 0.3/r. Enter Houston’s Law, I guess…? Not great, but not terrible either; a larger corpus and some more sophisticated mathematics would likely produce a better number.
If we play the same trick as above, making both x– and y-axes logarithmic to smooth out the curve, this it what we see:
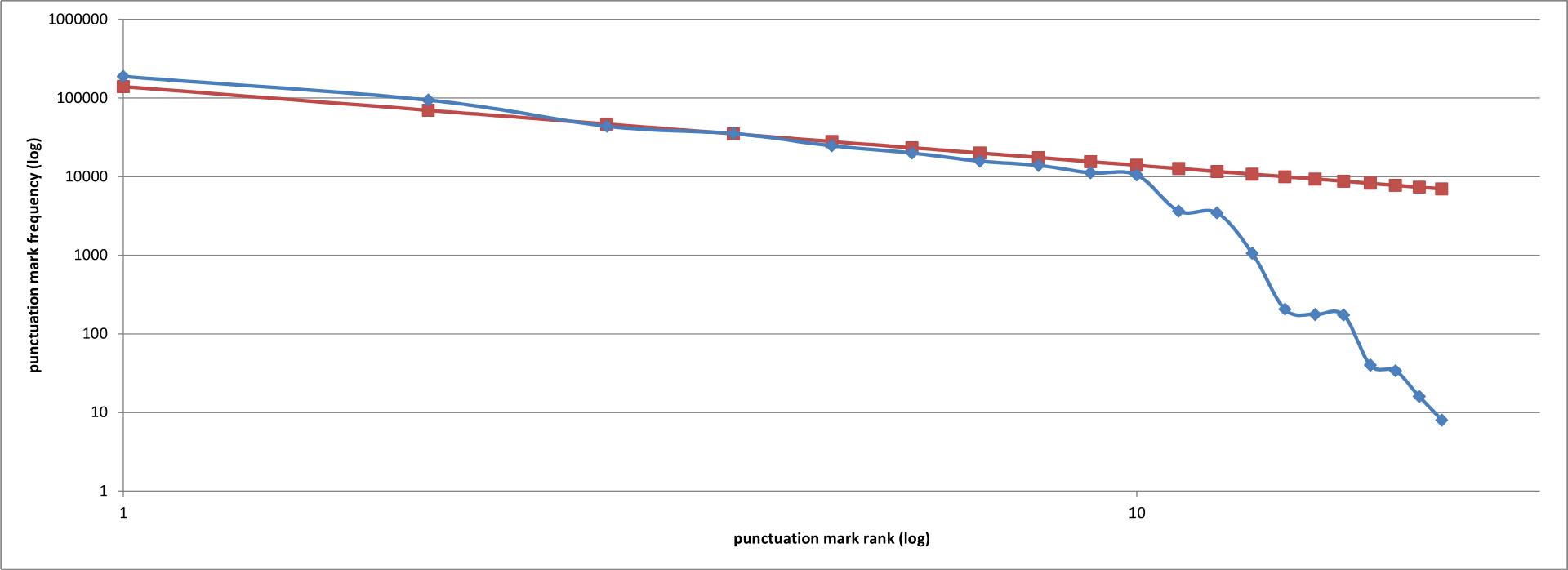
The first ten punctuation marks, then, follow a Zipfian distribtion in a quite striking way. The unhelpful behaviour of the last few marks (from ‘*’ to ‘%’) may well be because they’re either logograms or non-standard marks of punctuation; why the colon is under-represented, however, I’m not sure. Even so, this is all rather startling. Punctuation marks are Zipfian to a large degree, just like words; the frequency with which we use them obeys the same eerily ubiquitous inverse power law distribution, and I am none the wiser as to why. If ever there was a time to weigh in, commenters, this is it! What’s going on here, and why?
- 1.
-
The Harvard Crimson. “Zipf Dies After 3-Month Illness”.
- 2.
-
Weisstein, Eric W. “Zipf’s Law”. MathWorld. Accessed October 4, 2015.
- 3.
-
Francis, Nelson, and Henry Kucera. “Brown Corpus”. The Internet Archive.
- 4.
-
Weisstein, Eric W. “Benford’s Law”. MathWorld. Accessed October 4, 2015.
- *
- I picked the following works from Project Gutenberg’s list of most downloaded titles:
- A Modest Proposal
- A Tale of Two Cities
- Alice’s Adventures in Wonderland
- Frankenstein; Or, The Modern Prometheus
- Grimms’ Fairy Tales
- Metamorphosis
- Moby Dick; Or, The Whale
- Pride and Prejudice
- The Adventures of Sherlock Holmes
- The Adventures of Tom Sawyer
- The Count of Monte Cristo
- The Picture of Dorian Gray
- †
- It’s worth noting here that I chose to consider the paired marks — single and double quotation marks, parentheses and so on — as single marks for the purposes of this analysis, but there’s certainly room to look at them as two distinct units. ↢
Comment posted by Walter Underwood on
Probably not enough data. It takes an immense amount of data to get significant results very far down the curve. I call this “The Curse of Zipf”.
When I was working on search at Netflix, I had to collect 25 million search clicks to get useful data on only the top 3000 queries. And I used a very generous definition of “useful”, with a cutoff of 100 clicks.
Also, the vocabulary (distinct punctuation marks) is fairly small. Zipf usually falls apart at low frequencies.
I agree with the decision on the paired question marks. They are always used together.
I think the shallowness of the Zipf distribution is very interesting. To me, that suggests rules rather than a normal popularity distribution.
It would be interesting to compare to other rule-based distributions. In computer programs, compare keyword frequencies to variable name frequencies.
PS: The most common word in movie and TV titles is “2”.
Comment posted by NMillaz on
Would also be interesting to apply this to languages other than English, if the data were available. And re: your PS: the most common street name in America is Second St.
Comment posted by Keith Houston on
Hi Walter — thanks for the insightful comment! The small corpus did worry me. I’ve since downloaded the “baby” version of the British National Corpus and I intend to run through it when I get a moment.
Comment posted by Zeissmann on
On a slightly different topic – your post reminds me of something Keith wrote about a couple of posts ago about paragraphs in the age of the Internet. Namely, you put almost every sentence as a separate paragraph, blurring the distinction. Only, this comment section by default puts an indent at the start of every new paragraph, except for the first one, much like a well typeset book would, which makes your style rather conspicuous. So there you go, a proof that new media is already breaking people’s minds. :)
Comment posted by Screwtape on
Given that these power-law distributions appear in so many disparate fields of human endeavour, I have to assume that the common link between them is, well, humans. Human brains love to put things in hierarchies, gluing mental-bite-sized chunks into larger structures, and those into larger structures still, and (as any computer scientist knows) hierarchical structures are the natural home of logarithms, exponents, and power-law distributions of all kinds. It seems reasonable to me that whatever feature of human nature guides us toward gluing together smaller parts of speech with “the” or “of” also guides us toward gluing together smaller ideas with commas and periods.
And before somebody points out that this doesn’t explain Benford’s law because measured numbers aren’t subject to human meddling… well, they are: measured numbers are almost always reported in units where one of something is a common, human-scale occurrence.
Comment posted by Keith Houston on
Hi Screwtape — I think you’re right. There’s a human-imposed order in many distributions that isn’t always apparent at first, though working out how that ordering impetus is applied can be quite tricky!
Comment posted by Korhomme on
Fascinating. I see that Zifp was a professor of German; the examples you give are all in English. Does Zipf’s law work for languages other than English?
Comment posted by Dave Mattingly on
Korhomme, yes, Zipf’s law applies to every language.
Here’s a video explanation that goes into more depth but still keeps it understandable.
Comment posted by Korhomme on
Thanks. German has der, das, die, den and dem for the English ‘the’. Are these counted separately or together? And what about Latin where there isn’t a word for ‘the’? I guess the word rank varies from one language to another.
Comment posted by Tom on
Most of Project Gutenberg is in ASCII. Once you get further down the list of punctuation, you will end up with marks that can’t be correctly and consistently transcribed.
Comment posted by Keith Houston on
Hi Tom — that’s a good point! As Walter mentions above, however, you need a pretty significant sample size to get a reliable distribution for the least common marks. I imagine that non-standard marks probably fall into that category, so we’re probably not losing much if they aren’t transcribed correctly.
Comment posted by Jon of Connecticut on
Melville and Dickens used commas differently than we use them today, IIRC. In Confessions of a Comma Queen, Mary Norris mentions how those writers used them like the Greek playwrights used their komma;to mark where a speaker would pause while reading aloud.
Comment posted by Keith Houston on
Hi Jon — very true. I suspect that we’d see a Zipfian distribution in any sufficiently large body of text, however, even if the ordering of the marks changes between corpora.
Comment posted by derek on
Zipf laws aren’t just about people; asteroids and earthquakes follow them too. It seems to be about what happens when things break up, displace, or suppress other things just like them. Use of a comma lets you go just that little bit longer without a period. But use of a period delays the point at which you can insert your next comma.
Comment posted by Keith Houston on
Hi Derek — that’s an interesting point of view. I don’t know enough about Zipf/Benford/inverse power laws in nature to agree or disagree, but I can see what you mean. With punctuation, however, is there not a more sophisticated semantic structure in operation rather than a simple splitting up of sentences?
Comment posted by Jamsheed on
This is just amazing! I am in awe. (Hope to have something slightly more substantive tomorrow, but for now just thanks!)
Comment posted by Keith Houston on
Thanks! Glad you enjoyed the post.
Comment posted by Wide Spacer on
You don’t have enough data yet to fill in your smooth curve. In general, there may not be enough punctuation to give you a good data set. You are definitely dealing with typography issues (e.g. # was a handwriting symbol that for practical purposes didn’t exist in typography even into the 20th century). And you may be dealing with OCR issues—odd characters may be misread or dropped completely. Your lack of ampersands, common in old texts, also makes me wonder if Gutenburg automatically convereted ampersands to “and”.
Comment posted by Keith Houston on
Hi Wide Spacer — I plan to re-run the test on a larger sample of texts from Project Gutenberg when I get a chance, which should fill in some of the gaps.
That’s a good point about ampersands. The Project Gutenberg FAQ doesn’t go into specifics about how to transcribe unusual characters, though I suspect that most of their works are OCR’d from the most modern copies they can lay their hands on — and which in turn will tend to avoid using characters such as the ampersand.
Thanks for the comment!