I had the pleasure, recently, of writing another article for BBC Culture. It’s called “Punctuation that failed to make its mark” and it’s a sort of Shady Characters greatest hits, a compilation of a few of my favourite marks that tried valiantly but unsuccessfully to achieve widespread acceptance. There’s Martin K. Speckter’s evergreen interrobang, or ‘‽’, intended to punctuate an excited or rhetorical question; Bas Jacob’s clever but ill-fated ironiteken, or irony mark, as shown above; and the excellent quasiquote (″), or paraphrasing mark, first sent in to Shady Characters back in 2014 by the late Ned Brooks.
Like the first article, it was fun to write; also like the first article, it was often more difficult to choose what to take out rather than what to leave in. Have a read and, as ever, let me know what you think of it!
Update: the article is now available in Spanish at La Nacion.
Things have been frantic around here lately. Mostly, I’ve been busy reviewing the proofs of The Book, of which more soon, but I’ve also written a pair of articles for other publications, both of which were a lot of fun to address.
First up is this review for the Wall Street Journal of David Crystal’s new book, Making a Point: The Per(s)nickety Story of English Punctuation. (The optional s appears on the American edition.) David’s book combines a brief but entertaining history of punctuation in English with a series of short, pragmatic chapters on modern usage. He sticks with the standard marks — the comma, colon, full stop et al — but his anecdotes and asides make this a lively little book. Not as preachy as Eats, Shoots, and Leaves and, dare I say, playing a straighter bat than Shady Characters, I’d heartily recommend it to readers here.*
Separately, I was happy to come across an article in The Guardian about the arrival of the ellipsis in English literature. It quotes Dr Anne Toner, who I met a few months back at Punctuation in Practice, on how this odd little practice made its way from factual books into fiction. The first ellipses in fiction (in drama, in fact) were created in the 16th century using hyphens rather than dots (----), but things moved on rapidly from there:
By the 18th century, said Toner, it “becomes very common in print, and blanking starts to be used as a means of avoiding libel laws”, with series of dots starting to be seen in English works, as well as hyphens and dashes, to mark an ellipsis.
Embraced by writers from Percy Shelley to Virginia Woolf, it was in the novel that the ellipsis “proliferated most spectacularly”, according to Toner. She points to Ford Madox Ford and Joseph Conrad’s use of ellipses more than 400 times in their 1901 novel The Inheritors. Ford said that the writers were aiming to capture “the sort of indefiniteness that is characteristic of all human conversations, and particularly of all English conversations, that are almost always conducted entirely by means of allusions and unfinished sentences”.
You can read the full article here. If that whets your appetite, Anne has just published an entire book about elision in English literature entitled Ellipsis in English Literature: Signs of Omission; and if her talk at Punctuation in Practice is anything to go by, it’ll be a thorough and thought-provoking read.
Let’s try an experiment. If we start with some large body of text — post-war American novels, say, or twentieth-century British newspapers — and count all the occurrences of all the words in those texts, we can put together a fairly accurate list of the most popular words in English. The word “the” would be at the top, followed by “of” and then “and”. With this list of word counts in hand, you could turn to any other similar body of work — British novels or American newspapers, for example — and have a good idea of how often you’d expect to find each of the words on your list. Simple enough.
Next, imagine that you throw away those word counts. You keep only the list of words themselves, ordered from most to least common. You don’t know if “the” occurs twice as often as “of” or a hundred times more than it. It turns out that you can still predict how often you’re likely to encounter a given word: knowing only that “the” is the most common word, “of” is second most common, “and” is third, and so on, it is possible to guess with quite startling accuracy exactly how likely you are to encounter a given word. The mathematical relationship that underpins all this is called Zipf’s Law, named for its discovery in the 1930s by Kingsley Zipf, a professor of German at Harvard,1 and it is very simple indeed. Eric Weisstein’s excellent Mathworld site explains it as follows:
In the English language, the probability of encountering the rth most common word is given roughly by P(r) = 0.1/r for r up to 1000 or so.2
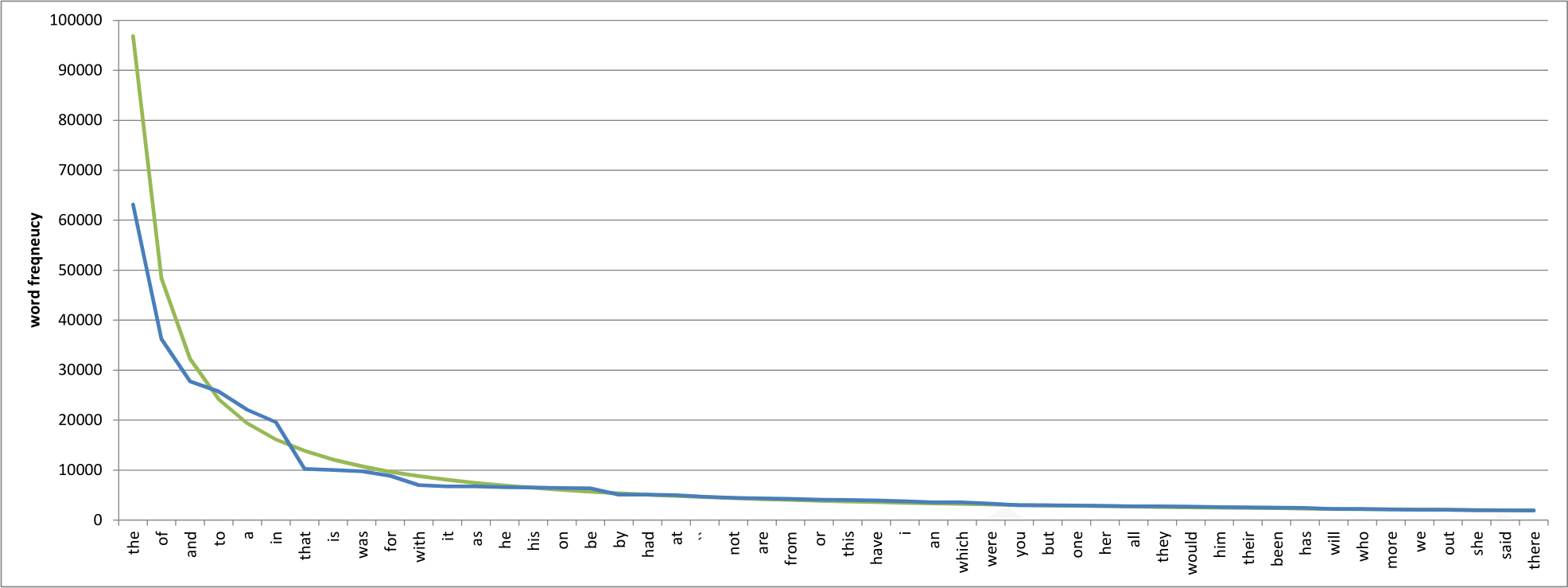
To put some numbers on it, you should encounter the word “the” around every ten words, equating to a probability of 0.1/1 = 0.1; “of” should occur every twenty words or so, from 0.1/2 = 0.05; “and” will appear once every thirty words or thereabouts, from 0.1/3; and so on. This is an instance of what is called an inverse power law, and if you plot these numbers on a logarithmic scale you get a shockingly straight line. Here’s an example of the raw numbers for the fifty most common words in the so-called Brown Corpus, a million-word collection of texts compiled between 1964 and 1979:3
Word counts (blue) in the Brown Corpus, ordered from most to least common. Also shown are the expected word counts according to Zipf’s Law (green). (Image by the author.)
Not bad, I think. I’ve overlaid the expected word counts (in green) as predicted by Zipf’s Law, and it looks fairly convincing. If we make each axis logarithmic rather than linear, we get this:
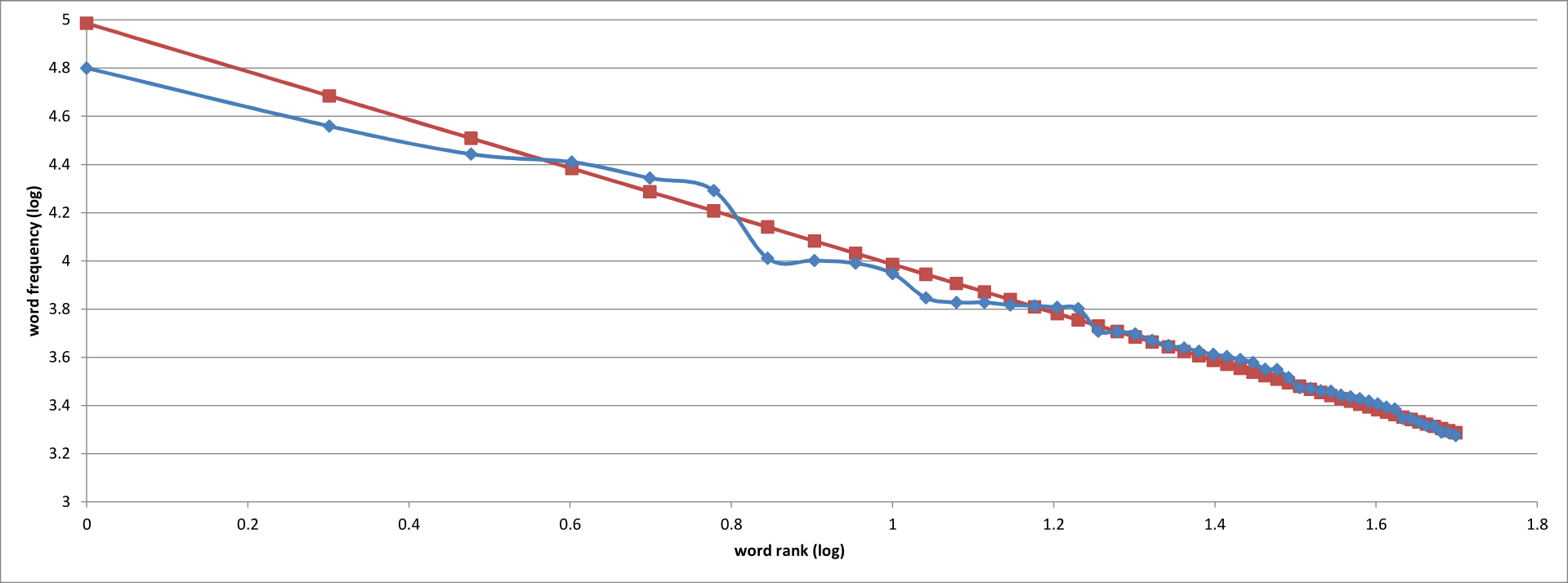
Word counts (blue) in the Brown Corpus, ordered from most to least common. Also shown are the expected word counts according to Zipf’s Law (green). Both x and y axes are logarithmic rather than linear. (Image by the author.)
Better! The maths behind this are quite involved, but the effect of viewing the data on logarithmic axes is to show the perfectly straight line predicted by Zipf’s Law. Again, our data looks good — not a perfect fit, but our actual word counts conform to the predicted values relatively closely. So far, so good. It look as though Zipf’s Law is in full effect in our million-word test case.
Now the weird thing about Zipf’s Law is that is can be arrived at only by observation. There are no verbs, conjunctions and or definite articles out there in nature, waiting for their physical properties to be discovered; our ancestors made them up as they went along and yet somehow we have constructed a language that adheres uncannily to an abstract mathematical idea. Why should the word “the” occur twice as often as “of”, three times as often as “and”, and so on? No-one really knows.
What is even odder is that inverse power laws crop up again and again in what should, by rights, be entirely random groups of things; Zipf’s Law is to words what Benford’s Law is to digits, and Benford’s Law is absolutely everywhere. The distribution of digits in house numbers, prime numbers, the half-lives of radioactive isotopes, and even the lengths in kilometres of the world’s rivers all follow inverse power laws, with the digit 1 being most prevalent by far and the others falling off behind it. Benford’s Law is so reliable that economists use it to detect fraud: if they don’t see a logarithmic distribution of digits in a given set of accounts, with 1 enthroned at the top, they know that someone has been doctoring the figures.4
My thought, then, was this: does punctuation follow some variant of Zipf’s Law? If we count all the marks of punctuation in some suitably large dataset of English texts, do we see a logarithmic distribution in them? There are many fewer unique punctuation marks than there are words, of course, but then Benford’s Law works quite happily with only ten digits to play with. It’s intriguing to wonder: were the writers and editors who invented the comma, full stop and apostrophe moved by the same inexplicable law that governs baseball statistics, the Dow Jones index and the size of files on your PC? I wrote a computer program to find out.
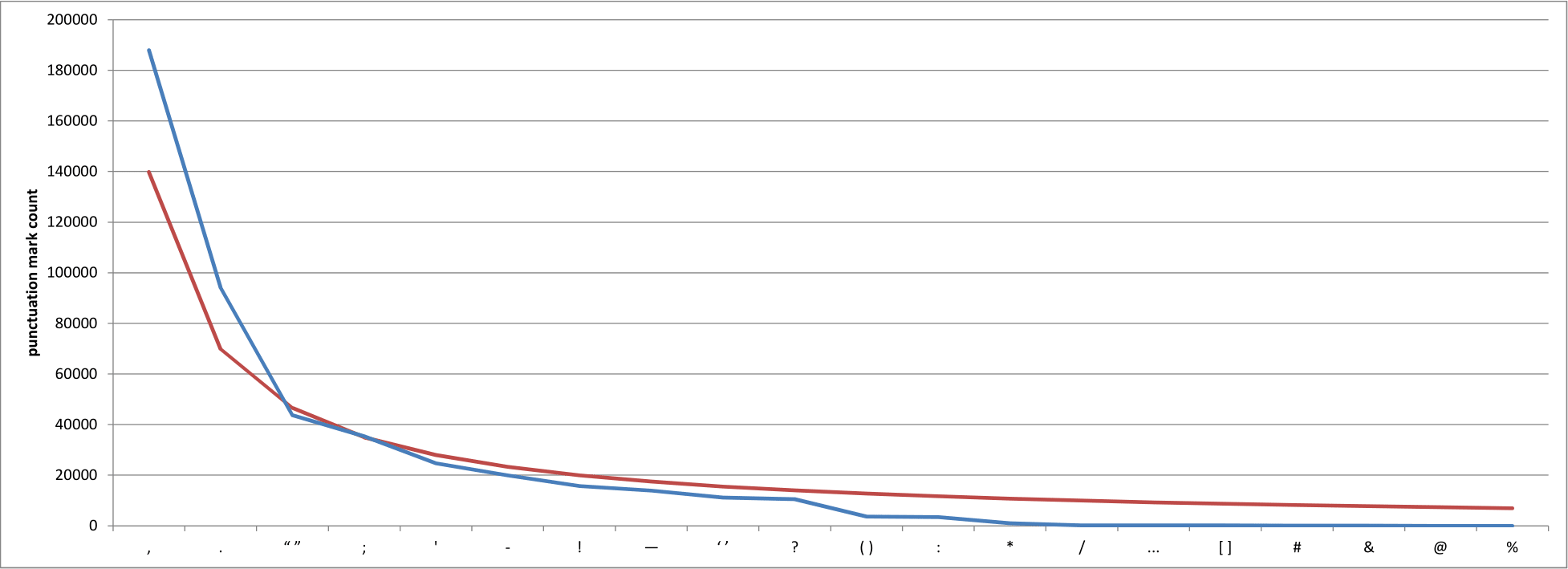
I started by looking at the Brown Corpus, but given that it contains a paltry million words or so there aren’t all that many punctuation marks to be found. I turned instead to Project Gutenberg, which makes out-of-copyright books available in a variety of formats, and downloaded twelve of the most popular works.* Next, I counted the occurrences of all marks of punctuation and plotted them both as raw numbers and as log-log graphs of their occurrences and rank numbers of those same values. Here’s the equivalent of our first graph, only for marks of punctuation rather than words:
Punctuation mark counts (blue) in a selection of works from Project Gutenberg, ordered from most to least common. Also shown are the projected counts (red). (Image by the author.)
Well then. This looks familiar.
We’ll come to the red line in a moment, but let’s stick with the blue line for now. It represents the number of times that each of the marks of punctuation along the x-axis occurred in my ad hoc Project Gutenberg corpus, with the comma in pole position and the full stop around 50% behind it. There’s a bit of a jump down to the paired quotation mark,† but the fact that the quotation mark is up there at all is doubtless to be expected from the dialog-heavy novels that make up the bulk of the works I analysed. The semicolon is is fourth position, likely because my texts are predominantly of the nineteenth century, and the apostrophe follows it in fifth.
Now to the red line. If you remember, Zipf’s Law says that the probability P of encountering a word with ranking r is given by P(r) = 0.1/r. Guessing that there’s a similar distribution for punctuation marks, I played around with a variety of different values for the numerator of the fraction, eventually settling on 0.3 as a reasonable proposition. The red line, then, is my predicted distribution of punctuation marks, as given by the equation P(r) = 0.3/r. Enter Houston’s Law, I guess…? Not great, but not terrible either; a larger corpus and some more sophisticated mathematics would likely produce a better number.
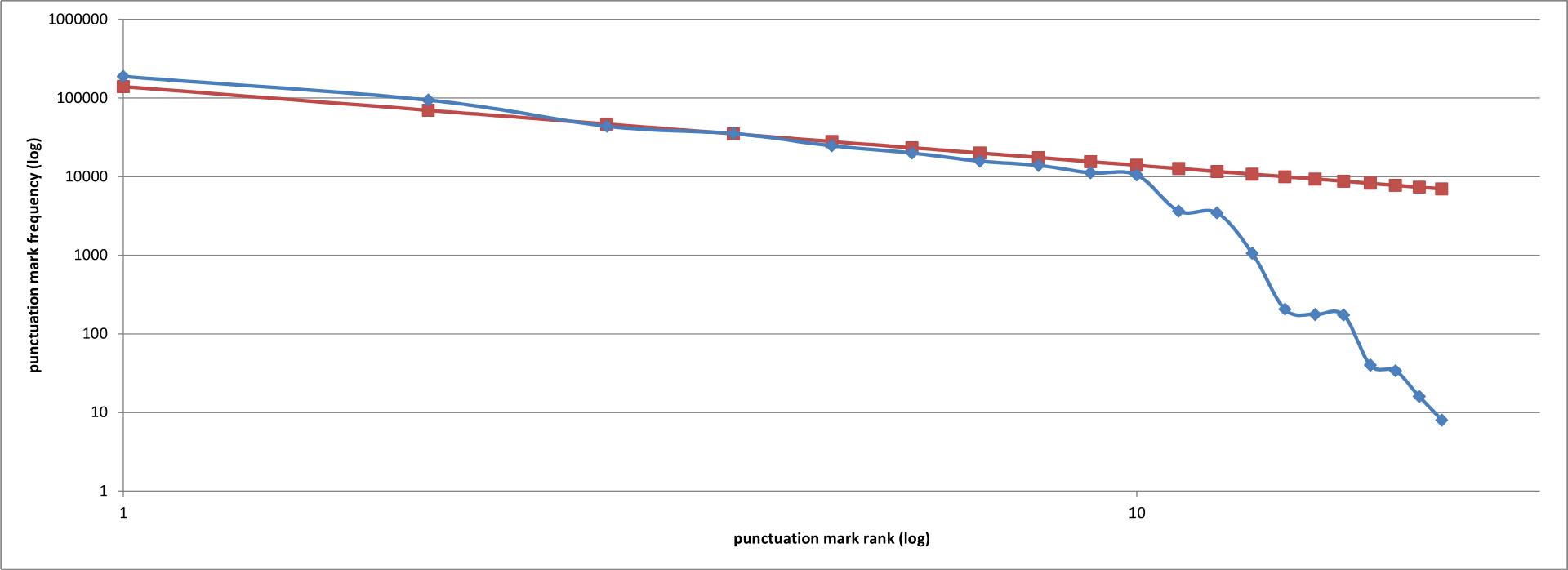
If we play the same trick as above, making both x– and y-axes logarithmic to smooth out the curve, this it what we see:
Punctuation mark counts (blue) in a selection of works from Project Gutenberg, ordered from most to least common. Also shown are the projected counts (red). Both axes are plotted on a logarithmic scale. (Image by the author.)
The first ten punctuation marks, then, follow a Zipfian distribtion in a quite striking way. The unhelpful behaviour of the last few marks (from ‘*’ to ‘%’) may well be because they’re either logograms or non-standard marks of punctuation; why the colon is under-represented, however, I’m not sure. Even so, this is all rather startling. Punctuation marks are Zipfian to a large degree, just like words; the frequency with which we use them obeys the same eerily ubiquitous inverse power law distribution, and I am none the wiser as to why. If ever there was a time to weigh in, commenters, this is it! What’s going on here, and why?
It’s worth noting here that I chose to consider the paired marks — single and double quotation marks, parentheses and so on — as single marks for the purposes of this analysis, but there’s certainly room to look at them as two distinct units. ↢
Palaeography is the study of old writing. And as often as I’ve had to hunt through old manuscripts for points (·), pilcrows (¶), virgules (/) and the like, I am not a palaeographer in anything more than the loosest sense. Given this, was a pleasant surprise to find myself chairing a session at a palaeography conference called DigiPal V, held at King’s College London just a couple of weeks ago. I was there at the invitation of Stewart Brookes, King’s College’s resident digital palaeography specialist, who kindly moved me sideways from presenter to chair when I pleaded an inability to come up with a decent paper in time.
You may remember Stewart’s name from my report on Punctuation in Practice, Elizabeth Bonapfel’s workshop on punctuation in all its forms, held a few months ago at Berlin’s Freie Universität. Stewart gave a talk there about marks of punctuation in copies of the manuscripts of Ælfric, a prolific Anglo-Saxon monk who wrote hagiographies, Catholic homilies, biblical commentaries and the like — you know, the usual Anglo-Saxon–monkish sort of thing. When he isn’t studying Ælfric’s works, however, Stewart is one of the managers of the DigiPal project, a website that, in its own words,
is a new resource for the study of medieval handwriting, particularly that produced in England during the years 1000–1100, the time of Æthelred, Cnut and William the Conqueror. It is designed to allow you to see samples of handwriting from the period and to compare them with each other quickly and easily.
For you and I, this translates into a website where you can pore over medieval manuscripts in quite exquisite detail, picking out archaic letters like the thorn (‘þ’, as covered here) or long-dead marks of punctuation like the punctus versus (‘;’ or thereabouts, representing a long pause analogous to a full stop). Now I’d known about DigiPal itself for some time, but the speakers during my session and others at the DigiPal conference opened my eyes to a whole new set of online palaeography resources. Here are just a few of them:
The UK National Archives host an excellent online course introducing the subject of palaeography. Their material focuses on the sixteenth–nineteenth centuries, but the basic principles are the same whatever the time period.
Oxford University’s Ancient Lives project is a crowdsourced attempt to transcribe the thousands of ancient Greek texts found at the site of the ancient city of Oxyryhnchus in Ptolemaic Egypt. If you fancy trying your hand at palaeography, this is a great place to get started; if you like the sound of that but would prefer something a little more recent, the AnnoTate project is using the same underlying software to transcribe artists’ notebooks. Both are very cool.
Models of Authority, built on the same software foundations as DigiPal, lets users browse and examine Scottish law charters of the twelfth and thirteenth centuries. It’s as easy to use as DigiPal, and though its content is fairly limited at the moment I am reassured that there is much more to come.
There is a world of open palaeographic learning out there for the benefit of amateurs and professionals alike, and I’m looking forward to finding out much more about it. Thank you to Stewart for inviting me along — chairing a session wasn’t nearly as terrifying as I had imagined it might be, and I’m already looking forward to DigiPal VI next year!
In lieu of a post this week, head over to BBC.com’s Culture section to read my article about “The Mysterious Origins of Punctuation” — it’s hot off the presses! Want to chat about it? Post a comment here or over at the related Facebook post. Shady Characters readers will be right at home, and I hope you enjoy it!
Update: the article is now available in Spanish too, at BBC Mundo.